2026. 4. 2. 17:15ㆍProject
KDT 과정의 마무리인 파이널프로젝트 주제가 확정 되었다. 나만의 DB 비서.
우리 팀은 파편화된 개인 데이터를 통합 학습하여, 사용자가 원하는 정답과 그 근거를 즉시 제시하는 '지능형 DB 비서' 구축을 목표로 삼았다.
1. 프로젝트의 목표: "개인 비정형 데이터의 자산화"
현대인은 매일 방대한 양의 PDF, 엑셀, 메모 등을 생성한다. 그러나 정작 중요한 정보를 찾기 위해서는 폴더를 뒤지거나 기억에 의존해야 하는 비효율이 발생한다. 우리는 사용자가 업로드한 모든 비정형 데이터를 AI가 이해하고, 자연어 질의에 대해 정확한 출처와 함께 답변하는 폐쇄형 개인 DB 시스템을 지향한다.
2. 핵심 기술: 하이브리드 검색(Hybrid Search) 엔진
일단 내가 맡은 부분은 텍스트 파일의 검색 기능이다. 사용자가 음성이나 텍스트로 해당 파일의 내용을 검색할 경우 그 내용을 찾아주고 이메일로 요약 및 해당 파일 전체를 전송해주는 기능이다. 하지만 단순한 키워드 매칭이나 벡터 검색만으로는 실전 서비스의 정확도를 담보할 수 없었다. 이에 따라 의미 기반의 Dense Embedding과 키워드 중심의 BM25를 결합한 하이브리드 방식으로 실험해보고 있다.
- Dense Embedding (80%): ko-sroberta-multitask 모델을 사용하여 문장의 맥락과 의도를 파악한다. 이는 "봄에 진행한 기획안"과 같은 추상적인 질문에 대응하는 핵심 동력이다.
- Sparse BM25 (20%): 특정 제품명이나 보안 코드(예: SEC-BO-206) 등 고유 명사를 정확히 포착하기 위해 키워드 가중치를 부여했다.
- 최적화: L2 정규화(Normalization)를 거친 벡터를 FAISS IndexFlatIP 인덱스에 저장하여 검색 속도와 정확도를 동시에 확보했다.
3. 설명 가능한 AI(XAI)의 구현
나의 DB비서는 검색 결과의 투명성을 높이기 위해 Score Breakdown 기능을 도입했다. 사용자에게 단순히 결과만 보여주는 것이 아니라, 해당 문서가 선정된 수학적 근거를 시각적으로 제시한다.

위 식을 바탕으로 각 결과 카드에 의미 점수와 키워드 점수의 기여도를 그래프로 표기하여 시스템에 대한 사용자의 신뢰도를 높였다.
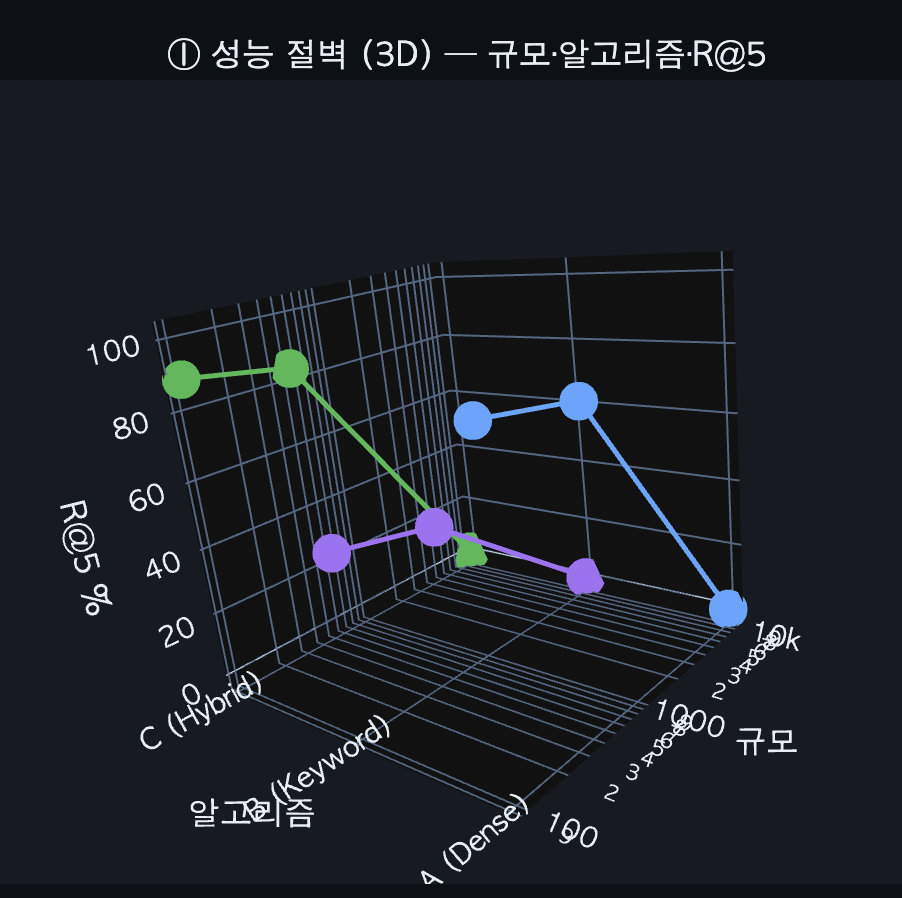
4. 실험적 발견: 성능 절벽(Performance Cliff)
개발 과정에서 데이터 규모에 따른 성능 변화를 관찰하기 위해 100개부터 10,000개(약 50,000개 청크)까지 스트레스 테스트를 진행했다. 실험 결과, 데이터 밀도가 일정 수준을 넘어서면 유사 벡터 간의 간섭으로 인해 정확도가 급감하는 '성능 절벽' 현상을 데이터로 확인했다.
그리고 이 결과를 팀원들과 공유하니, 팀장님께서 데이터의 양을 차례로 늘리는 방식이 아닌 한 번에 훅 늘려서 유사도가 떨어진 것 같다는 의견을 주셨다. 생각해보니, 내가 100개 -> 500개 -> 10,000개로 급작스럽게 늘리긴 했었다! (왜 이 생각을 못 했지? 500개까지는 잘 찾아오길래 갑자기 수를 확 늘린게 화근이 됐었다....) 특히 실제 데이터가 아닌 더미데이터로 실험을 해본 거라 이제 실제 문서용으로 파라미터를 찾는 실험을 해볼 생각이다. 이를 통해 향후 대규모 데이터 환경에서는 리랭커(Reranker) 도입과 시맨틱 청킹(Semantic Chunking)이 필수적이라는 기술적 통찰을 얻었다. 하지만 아직 실제 데이터셋으로 실험을 해보진 않아서, 데이터양이 많아질 경우 해당 방법을 도입할 생각.

5. 향후 과제: 실전 데이터(Real-world Data) 대응
현재 정제된 텍스트 기반의 실험을 마치고, 실제 업무 환경에서 쓰이는 복잡한 파일 형식들을 정복할 준비를 마쳤다.
- 다단 구조와 표가 포함된 고난도 PDF
- 국내 행정 문서의 표준인 HWP
- 반정형 데이터의 핵심인 XLSX(Excel) -> 일단 보류. PDF 먼저 잘 찾아 오는지 실험 할 것임
"가장 난도 높은 데이터를 먼저 해결해야 범용적인 성능을 보장할 수 있다"는 전략 하에, 공공기관 보도자료 및 기업 사업보고서 등 실제 파일을 활용한 극한의 테스트를 이어갈 계획이다. 벌써부터 트러블슈팅이 넘쳐난다. 후..
http://file:///Users/jangjuyeon/FP_Chainers/modaflow_viz/modaflow_report.html
'Project' 카테고리의 다른 글
| [DB 비서 Project] 데이터 전처리 Prefix 적용 전 vs 후 (0) | 2026.04.06 |
|---|---|
| [DB 비서 Project] 실전 데이터 임베딩 및 3D 시각화 분석 (0) | 2026.04.05 |
| [Meat-A-Eye 배포] 마지막 트러블 슈팅 (0) | 2026.03.30 |
| [Meat-A-Eye 배포] API -> SSL 인증 오류 (0) | 2026.03.29 |
| [Meat-A-Eye 배포] GPU 다이어트 (0) | 2026.03.28 |